-
 Thanh toán đa dạng, linh hoạtChuyển khoản ngân hàng, thanh toán tại nhà...
Thanh toán đa dạng, linh hoạtChuyển khoản ngân hàng, thanh toán tại nhà... -
 Miễn Phí vận chuyển 53 tỉnh thànhMiễn phí vận chuyển đối với đơn hàng trên 1 triệu
Miễn Phí vận chuyển 53 tỉnh thànhMiễn phí vận chuyển đối với đơn hàng trên 1 triệu -
 Yên Tâm mua sắmHoàn tiền trong vòng 7 ngày...
Yên Tâm mua sắmHoàn tiền trong vòng 7 ngày...
SQL for Data Science: Data Cleaning, Wrangling and Analytics with Relational Databases (Data-Centric Systems and Applications)
-

- Mã sản phẩm: 3030575918
- (2 nhận xét)


100% Hàng chính hãng
Chính sách Đổi trả trong vòng 14 ngày
Kiểm tra hàng trước khi thanh toán
Chưa có nhiều người mua - cẩn thận
- Publisher:Springer; 1st ed. 2020 edition (November 10, 2020)
- Language:English
- Paperback:300 pages
- ISBN-10:3030575918
- ISBN-13:978-3030575915
- Item Weight:1.02 pounds
- Dimensions:6.1 x 0.68 x 9.25 inches
- Best Sellers Rank:#3,052,330 in Books (See Top 100 in Books) #1,079 in Database Storage & Design #1,509 in Computers & Technology Industry #6,474 in Databases & Big Data
- Customer Reviews:4.0 out of 5 stars 2Reviews
2,051,000 vnđ
-
+
SQL for Data Science: Data Cleaning, Wrangling and Analytics with Relational Databases (Data-Centric Systems and Applications)
2,051,000 vnđ

(0 nhận xét)
- Chiết xuất từ 11 loại RAU CỦ QUẢ được trồng bằng phương pháp HỮU CƠ cực kỳ thơm ngon, an toàn cho bé ăn dặm và cả gia đình.
- KHÔNG CHẤT BẢO QUẢN, KHÔNG CHỨA CHOLESTEROL nên dùng được cho cả người huyết áp cao, máu nhiễm mỡ.
- Bổ sung lượng vitamin cần thiết cho cơ thể
- Hạt nêm mềm, mịn, có vị thanh ngọt, nêm nếm vào các món nấu, hầm, xào đều rất ngon
- Dùng được cả cho món chay và món mặn, giúp món ăn trở nên tròn vị và dậy mùi hơn.
50,000đ
-25%

(0 nhận xét)
- Thiết kế dạng nút nhỏ gọn, dễ dàng mang theo và sử dụng. Cải thiện tối đa các nhược điểm của băng vệ sinh thông thường.
- Sử dụng công nghệ StayDry độ thấm hút nhanh, mang lại cảm giác khô thoáng và bảo vệ đáng tin cậy.
- Thiết kế rãnh xoắn mở giúp thấm hút nhanh và khô thoáng, đồng thời tạo độ chèn khít giúp bảo vệ tuyệt đối và chống tràn một cách hiệu quả.
- Không chứa chất độc hại, không chứa chất tẩy trắng, không có nước hoa, không gây kích ứng và khó chịu cho vùng nhạy cảm.
- Sản phẩm có băng rút được cải thiện, giúp dễ dàng hơn trong quá trình sử dụng.
- Băng vệ sinh đã được kiểm duyệt phụ khoa.
135,000đ
180,000 đ

(1 nhận xét)
- Bổ phổi, đặc biệt tốt cho người bị viêm phổi phế quản mãn tính giảm nguy cơ mắc bệnh hen và các vấn đề về đường hô hấp.
- Giúp bồi bổ cơ thể, hỗ trợ ăn ngon, ngủ khỏe, tăng cường tuổi thọ.
- Tăng cường khả năng sinh lý ở nam giới.
- Làm giảm huyết áp và tăng cường quá trình lưu thông máu.
- Hỗ trợ sức khỏe tim mạch khỏe mạnh.
450,000đ
-39%

(0 nhận xét)
- Thiết kế mềm, tia sữa giúp bé chống bị sặc.
- Giúp bé chỉnh nha chống vẩu, tránh được các tật như hô, răng mọc lệch ở trẻ.
- Van chống sặc, nghẹn và giúp bé không bị đầy hơi.
- Thiết kế tiện lợi bình sữa cổ rộng cho phép mẹ dễ dàng pha sữa và vệ sinh bình sữa bằng tay mà không cần sử dụng các loại cọ bình sữa chuyên biệt.
135,000đ
220,000 đ

(0 nhận xét)
- Giúp bé thoải mái, tự do khi vận động.
- Chất liệu vải không dệt giúp hấp thụ chất thải lỏng nhanh chóng giữ cho bé luôn được khô thoáng.
- Nhờ công nghệ Airflow có khả năng trao đổi khí và thân thiện với làn da nhạy cảm của bé
- Bỉm Bella Happy sẽ đồng hành cùng bé từ tư thế nằm, lăn sang bò và ngồi, đến lúc bé dần dần trở nên cứng cáp hơn để đứng vững trên đôi chân non nớt của mình và tập đi.
100,000đ
-50%

(0 nhận xét)
- Đạt chứng nhận của FDA Hoa Kỳ.
- Kết quả đo sẽ được hiển thị ngay lập tức chỉ sau 1 giây.
- Sử dụng tia hồng ngoại cho phép đo nhiệt độ mà không cần tiếp xúc (khoảng cách đo 1 đến 5cm) với trán hay bề mặt, giúp giảm thiểu tối đa sự lây nhiễm chéo các bệnh truyền nhiễm.
- Tích hợp các nút chức năng ở 2 bên thân máy: Nút tắt mở âm thanh: Tắt/mở âm thanh phù hợp khi đo trong lúc bé đang ngủ. Nút MODE: Điều chỉnh các chế độ đo khác nhau. Nút MEM: Xem lại lịch sử đo với khả năng ghi nhớ kết quả của 20 lần đo trước đó.
- Màn hình LCD hiển thị rõ nét các thông số như: chế độ đo đang sử dụng, kết quả đo nhiệt độ, thời lượng pin của máy, tình trạng âm thanh.
- Màu màn hình báo hiệu tình trạng sức khỏe: Màu xanh lá cây: Thân nhiệt bình thường; Màu đỏ: Triệu chứng sốt.
- Đa năng: có thể sử dụng đo trán, đo tai cho trẻ em và người lớn, đồng thời có thể đo nhiệt độ phòng, đo nhiệt độ sữa hoặc thức ăn cho trẻ.
- Được làm bằng chất liệu nhựa cao cấp nhỏ gọn, cầm tay tiện lợi với khay lắp pin được thiết kế chống rơi. Bạn có thể đo nhiệt độ dễ dàng chỉ với một nút ấn ngay trên thân máy.
158,000đ
315,000 đ
-25%

(4 nhận xét)
✔ Viên uống Immune Support Supplement tăng cường miễn dịch, giúp bảo vệ cơ thể trước sự tấn công của virus, vi khuẩn
✔ Làm giảm nguy cơ nhiễm trùng đường hô hấp, bệnh cảm lạnh, cảm cúm
✔ Bổ sung vitamin C, D3 và kẽm cho cơ thể, ngừa thiếu chất do ăn uống
✔ Ngăn ngừa các rối loạn xương, giúp xương chắc khỏe.
✔ Giúp cân bằng rất nhiều nội tiết tốt trong cơ thể.
✔ Cải thiện sức khỏe tim mạch của bạn, giảm cholesterol xấu và làm tăng cholesterol tốt.
300,000đ
400,000 đ
-10%

(5 nhận xét)
- Hỗ trợ dự phòng bệnh sa sút trí tuệ do nguyên nhân mạch máu
- Hỗ trợ dự phòng nhồi máu cơ tim và não
- Làm giảm sự phát triển của khối ung thư
- Giảm nguy cơ gây ung thư đại tràng.
- Giảm đau đầu, đau lưng, đau cơ tay chân do cường độ làm việc nặng.
- Giảm đau răng hiệu quả, nhanh chóng.
- Giảm lượng kích thích tố Prostaglandin.
- Cải thiện bệnh nghẽn mạch vành tim.
- Hỗ trợ bệnh nhân tai biến mạch máu não.
- Khắc phục bệnh rung tâm nhĩ.
189,000đ
210,000 đ
-50%

(0 nhận xét)
- Hỗ trợ điều trị các triệu chứng dị ứng đường hô hấp dành cho trẻ từ 2- 12 tuổi
- Làm giảm triệu chứng sốt cỏ khô ở trẻ
- Loại bỏ nhanh triệu chứng nghẹt mũi và làm thông mũi.
- Giảm nhanh triệu chứng dị ứng mà không gây buồn ngủ
68,000đ
135,000 đ

(1 nhận xét)
- Cung cấp Biotin cùng các dưỡng chất cần thiết khác giúp nuôi dưỡng tóc và móng tay.
- Tăng độ dày cho tóc, móng tay và móng chân.
- Hỗ trợ phòng ngừa viêm da nhờn.
- Cải thiện tình trạng tóc khô, xơ, chẻ ngọn do thiếu các tinh chất dưỡng ẩm, giúp phục hồi mái tóc tóc bị hư tổn. Từ đó, giúp tóc chắc khỏe hơn.
- Giảm thiểu tình trạng rụng tóc, giúp mang lại một mái tóc óng mượt, bồng bềnh.
- Kích thích sự phát triển tế bào của móng tay và tóc giúp tóc mọc nhanh chóng hơn.
- Giảm nguy có sạm da, nám da. Giúp mang lại một làn da khỏe mạnh, sáng hồng.
- Hỗ trợ ngăn ngừa bong da tay, da chân, phòng ngừa chứng viêm da đầu do dịch nhờn từ chân tóc tiết ra.
535,000đ
-12%

(3 nhận xét)
-Tăng cường trí nhớ cho trẻ
- Cải thiện thị lực cho trẻ
- Tác dụng bổ não
- Cung cấp DHA cho sự phát triến não bộ của thai nhi, giúp trẻ thông minh vượt bậc.
1,059,000đ
1,200,000 đ
-5%

(1 nhận xét)
- Thành phần thảo dược giúp cải thiện xuất tinh sớm.
- Tăng cường sự dẻo dai cho nam và khoái cảm cho nữ.
- Cải thiện sinh lý nam và nữ một cách an toàn.
- Hỗ trợ cân bằng hooc môn và tăng cường sức khỏe sinh sản cho cả nam và nữ.
- Cải thiện số lượng và chất lượng tinh trùng.
400,000đ
420,000 đ
-24%

(0 nhận xét)
- Bổ sung Crom cho cơ thể bạn, giúp chuyển hóa glucid, lipid, protid, cung cấp năng lượng cho cơ thể.
- Làm tăng độ nhạy cảm của insulin, duy trì mức độ ổn định của đường trong máu
- Giúp gia tăng lượng Cholesterol tốt, ngăn ngừa tích tụ mỡ trong thành mạch, điều hòa huyết áp ở người cao tuổi, giảm nguy cơ nhồi máu cơ tim, bảo vệ tim mạch
550,000đ
720,000 đ
-8%

(0 nhận xét)
- Giúp tuyến giáp phục hồi và lượng Hormone được cân bằng, ổn định.
- Cung cấp chất chống Oxy hóa.
- Cải thiện tiêu hóa trong cơ thể.
- Giúp tuyến giáp không hoạt động quá mức gây suy nhược.
690,000đ
749,000 đ
(22 nhận xét)
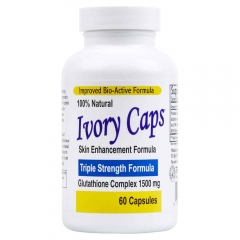
- Ngăn chặn quá trình oxy hóa của da
- Ngăn ngừa hắc sắc tố melanin (nám) của da.
- Ổn định nội tiết tố ngăn ngừa xạm da do nội tiết.
- Loại bỏ các tế bào hắc sắc tố melanin của da, làm giảm nguy cơ xạm da từ trong cơ thể, trị sạm, nám
- Giúp cải thiện chức năng gan, giải độc cơ thể và tăng cường hệ miễn dịch.
605,000đ

(1 nhận xét)
- Bổ sung chất xơ, giúp cân bằng hệ vi sinh đường ruột, tăng cường lợi khuẩn có lợi cho hệ tiêu hóa.
- Giúp hệ tiêu hóa thải các chất độc tố ra khỏi cơ thể hiệu quả.
- Hỗ trợ cải thiện tốt các bệnh lý về đại tràng như: viêm đại tràng co thắt (hội chứng ruột kích thích/ rối loạn chức năng đại tràng), viêm đại tràng giả mạc, viêm loét đại tràng,
- Cải thiện các triệu chứng rối loạn tiêu hóa như: bệnh táo bón, khó tiêu, tiêu chảy,...
- Giúp tái tạo niêm mạc đại tràng, tăng cường sức khỏe đường tiêu hóa, từ đó tăng cường hệ miễn dịch cho cơ thể.
229,000đ
(0 nhận xét)
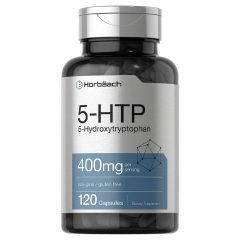
- Viên uống giúp giảm stress, giảm lo âu, chống trầm cảm.
- Giảm tình trạng và tần suất của chứng đau nửa đầu.
- Cân bằng cảm xúc, cải thiện tâm trạng, giúp bạn bình tĩnh hơn.
- Hỗ trợ hệ thần kinh khỏe mạnh, phòng ngừa suy nhược thần kinh.
- Cải thiện chất lượng giấc ngủ, giảm tình trạng mất ngủ.
700,000đ

(2 nhận xét)
- Tăng cường sức khoẻ, sự bền bỉ của cấu trúc xương khớp
- Ngăn chặn sự phá huỷ của các enzym đối với sụn khớp.
- Làm chậm quá trình lão hoá khớp xương và sụn.
- Cung cấp Glucosamine và Chondroitin cho xương, sụn, khớp.
- Bổ sung chất bôi trơn cho khớp và lớp đệm của sụn.
- Giúp các khớp và xương vận động linh hoạt, dễ chịu.
- Cải thiện được các chứng đau nhức xương khớp, viêm khớp.
765,000đ

(2 nhận xét)
✔ Phòng ngừa và hỗ trợ điều trị tai biến mạch máu não, đau thắt ngực.
✔ Bổ tim mạch và ngăn nừa đột quỵ
✔ Hỗ trợ điều trị bệnh tăng giảm huyết áp.
✔ Tăng cường tuần hoàn não và lưu thông máu.
✔ Tăng cường sinh lực, cải thiện tình trạng mệt mỏi và suy giảm trí nhớ ở người cao tuổi
555,000đ

(0 nhận xét)
- Khả năng giữ nếp tốt
- Không bị vón cục
- Không gây nhờn rít
- Phù hợp sáng tạo với mọi loại kiểu tóc.
- Khô nhanh và tạo cảm giác bồng bềnh tự nhiên và dễ dàng chỉnh sửa kiểu tóc bằng tay
590,000đ


Copyright ©2024 muathuoctot.com. All Rights Reserved
 KHUYẾN MÃI LỚN
KHUYẾN MÃI LỚN Đông Trùng Hạ Thảo
Đông Trùng Hạ Thảo Hỗ Trợ Xương Khớp
Hỗ Trợ Xương Khớp Bổ Não & Tăng cường Trí Nhớ
Bổ Não & Tăng cường Trí Nhớ Bổ Sung Collagen & Làm Đẹp
Bổ Sung Collagen & Làm Đẹp Bổ Thận, Mát Gan & Giải Độc
Bổ Thận, Mát Gan & Giải Độc Chăm Sóc Sức khỏe Nam Giới
Chăm Sóc Sức khỏe Nam Giới Chăm Sóc Sức khỏe Nữ Giới
Chăm Sóc Sức khỏe Nữ Giới Chăm sóc Sức khỏe Trẻ Em
Chăm sóc Sức khỏe Trẻ Em Thực Phẩm Giảm Cân, Ăn Kiêng
Thực Phẩm Giảm Cân, Ăn Kiêng Bổ Sung Vitamin & Khoáng Chất
Bổ Sung Vitamin & Khoáng Chất Bổ Tim Mạch, Huyết Áp & Mỡ Máu
Bổ Tim Mạch, Huyết Áp & Mỡ Máu Bổ Mắt & Tăng cường Thị lực
Bổ Mắt & Tăng cường Thị lực Điều Trị Tai Mũi Họng
Điều Trị Tai Mũi Họng Sức Khỏe Hệ Tiêu hóa
Sức Khỏe Hệ Tiêu hóa Chăm Sóc Răng Miệng
Chăm Sóc Răng Miệng Chống Oxy Hóa & Tảo Biển.
Chống Oxy Hóa & Tảo Biển.
{kind=link}
{kind=link}
{kind=link}